
Message Passing & Aggregation
Message Passing & Aggregation #
Author: Christoph Würsch, ICE
A Comparative Analysis of GraphSAGE, HAN, and HGT Graph Neural Networks #
Table of Contents
- Core GNN Concepts: Message Passing & Aggregation
- GraphSAGE (Graph Sample and Aggregate)
- HAN (Heterogeneous Graph Attention Network)
- HGT (Heterogeneous Graph Transformer)
- Conclusion
- References
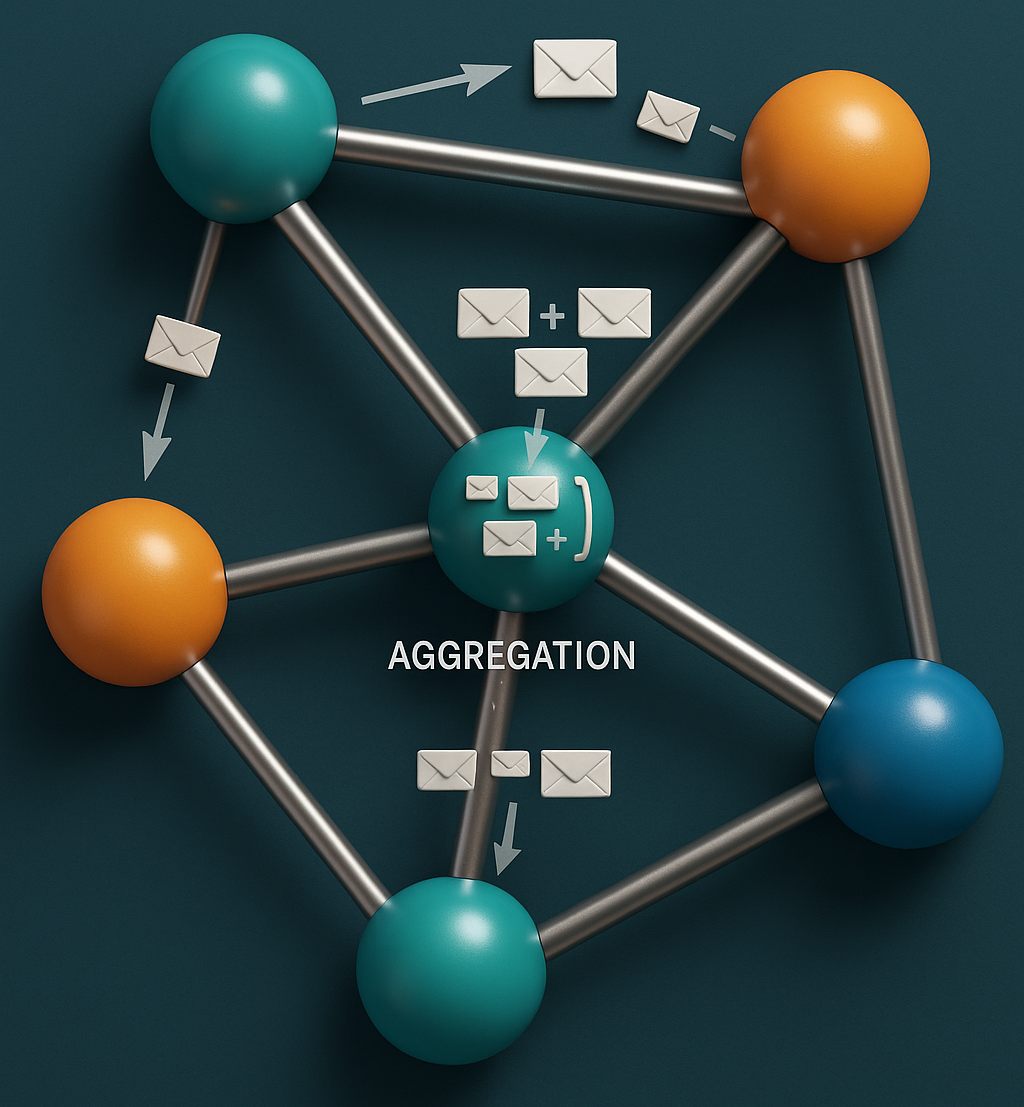
Core GNN Concepts: Message Passing & Aggregation #
At their core, most GNNs operate on a neighborhood aggregation or message passing framework. This process allows nodes to iteratively update their feature representations (embeddings) by incorporating information from their local neighborhoods. A single layer of a GNN can be generally described by three key steps:
-
Message Passing: For a target node , each neighboring node generates a “message” . This message is typically a function of the neighbor’s feature vector .
-
Aggregation: The target node aggregates all incoming messages from its neighbors into a single vector, . The
AGGREGATEfunction must be permutation-invariant (e.g., sum, mean, max) as the order of neighbors is irrelevant. -
Update: The node updates its own embedding by combining its previous embedding with the aggregated message .
Here, denotes the -th layer of the GNN. The models we discuss below are specific instantiations of this general framework.
GraphSAGE (Graph Sample and Aggregate) #
GraphSAGE [1] was designed to be a general, inductive framework that can generate embeddings for previously unseen nodes. Its key innovation is not training on the full graph but on sampled local neighborhoods. The primary innovation of GraphSAGE is its inductive capability, which allows it to generalize to previously unseen nodes. This makes it exceptionally well-suited for dynamic, large-scale graphs where the entire graph structure is not available during training.
One of the most prominent applications is in the domain of social networks and content recommendation. In the original paper, GraphSAGE was used for node classification on the Reddit dataset to classify post topics [1]. A landmark industrial application is PinSAGE, a GNN-based recommender system developed by Pinterest. PinSAGE uses GraphSAGE’s principles to recommend “pins” (images) to users by learning embeddings for billions of items in a dynamic web-scale graph. It effectively handles the challenge of generating recommendations for new, unseen content on a daily basis [2]. Its success has made it a blueprint for modern GNN-based recommender systems.
Instead of using the entire neighborhood for aggregation, GraphSAGE uniformly samples a fixed-size set of neighbors at each layer. This ensures that the computational footprint for each node is fixed, making the model scalable to massive graphs. GraphSAGE is primarily designed for homogeneous graphs, where all nodes and edges are of the same type.
Mathematical Formulation #
For a target node at layer , the process is as follows:
- Sample Neighborhood: Sample a fixed-size neighborhood from the full set of neighbors .
- Aggregate: Aggregate the feature vectors from the sampled neighbors. The Mean aggregator is a common choice:
- Update: Concatenate the node’s own representation from the previous layer, , with the aggregated neighbor vector. This combined vector is then passed through a fully connected layer with a non-linear activation function . where is a trainable weight matrix for layer .
HAN (Heterogeneous Graph Attention Network) #
HAN [3] is specifically designed to work with heterogeneous graphs, which contain multiple types of nodes and edges. It acknowledges that different types of nodes and relationships contribute differently to a task. HAN’s strength lies in its ability to leverage predefined semantic relationships (meta-paths) to generate task-aware node representations in heterogeneous graphs. This is particularly useful in domains where expert knowledge can guide the model’s focus.
The canonical application for HAN is in academic network analysis. As demonstrated in the original paper, HAN can effectively classify research papers or authors in bibliographic networks like DBLP and ACM by utilizing meta-paths such as Author-Paper-Author (co-authorship) and Author-Paper-Subject-Paper-Author (shared research topics) [3]. Another critical application area is fraud and anomaly detection. In financial or e-commerce networks, relationships between users, devices, IP addresses, and transactions are heterogeneous. By defining meta-paths that capture known fraudulent patterns (e.g., User-Device-User), HAN can learn powerful embeddings to identify malicious actors. While many industrial systems are proprietary, research from companies like Alibaba has shown the power of heterogeneous GNNs for this purpose [4].
HAN uses a hierarchical attention mechanism. First, node-level attention learns the importance of different neighbors within a specific relationship type (meta-path). Second, semantic-level attention learns the importance of the different meta-paths themselves. A meta-path is a sequence of relations connecting two node types (e.g., Author Paper Author).
Mathematical Formulation #
Let be a meta-path.
- Node-Level Attention: For a node and its neighbors connected via meta-path , HAN learns attention weights for each neighbor . The embedding for node specific to this meta-path is an aggregation of its neighbors’ features, weighted by attention:
- Semantic-Level Attention: After obtaining semantic-specific embeddings , HAN learns weights for each meta-path. The final embedding is a weighted sum:
A meta-path is a predefined sequence of node types and edge types that describes a composite relationship (a “semantic path”) between two nodes. For example, in a scientific collaboration network with Authors (A), Papers (P), and Subjects (S), a meta-path Author-Paper-Author (APA) represents the co-author relationship. Another meta-path, Author-Paper-Subject-Paper-Author (APSPA), could represent the relationship between two authors who have written papers on the same subject. HAN leverages these user-defined paths to group neighbors by semantics.
Step 1: Node-Level Attention #
The first level of attention aims to answer the question: Within a single semantic path, which neighbors are most important for a given node?
For a specific meta-path , a central node has a set of neighbors . The node-level attention mechanism learns to assign different importance weights to these neighbors.
-
Feature Transformation: Since different node types may have different feature spaces, their initial feature vectors () are first projected into a common space using a type-specific transformation matrix , where is the type of node . For simplicity in this explanation, we assume features are already in a common space.
-
Attention Coefficient Calculation: For a pair of nodes connected via meta-path , the attention coefficient is calculated. This measures the importance of node to node . It is parameterized by a learnable attention vector specific to the meta-path:
where is a shared linear transformation matrix applied to the features of each node, and denotes concatenation.
-
Normalization: The attention coefficients are then normalized across all neighbors of node using the softmax function to obtain the final attention weights . These weights represent a probability distribution of importance over the neighbors.
-
Aggregation: Finally, the semantic-specific embedding for node , , is computed as a weighted sum of its neighbors’ transformed features.
where is a non-linear activation function (e.g., ELU).
This process is repeated for every defined meta-path, resulting in a set of semantic-specific embeddings for each node .
Step 2: Semantic-Level Attention #
After obtaining different embeddings for each semantic path, the second level of attention answers the question: For a given node, which semantic path is the most important?
-
Importance Weight Calculation: HAN learns the importance of each meta-path for a node . This is achieved by first transforming each semantic-specific embedding (e.g., through a linear layer and tanh activation) and then measuring its similarity to a shared, learnable semantic-level attention vector .
where and are learnable parameters, and the weights are averaged over all nodes in the graph.
-
Normalization: These importance weights are also normalized using a softmax function to obtain the final semantic weights .
-
Final Aggregation: The final node embedding is a weighted average of all its semantic-specific embeddings, using the learned semantic weights .
This final embedding is a rich representation that has selectively aggregated information from the most relevant neighbors and the most relevant relationship types.
Instructive Example: Scientific Collaboration Network #
Let’s consider a graph with Authors, Papers, and research Subjects. Our goal is to generate an embedding for a target author, Dr. Eva Meyer. We define two meta-paths:
- (APA): Represents the co-author relationship.
- (APSPA): Represents authors working on similar subjects.
Node-Level Attention in Action:
- For meta-path APA, Dr. Meyer’s neighbors are her co-authors: Prof. Schmidt and Dr. Chen. The node-level attention might learn that for predicting future research topics, Prof. Schmidt’s work is more influential. Thus, it assigns a higher weight: , . The embedding will therefore be heavily influenced by Prof. Schmidt’s features.
- For meta-path APSPA, Dr. Meyer’s neighbors are authors who publish on the same subjects, like Dr. Lee and Prof. Ivanova. Here, the attention might find both to be equally important, resulting in weights like and .
Semantic-Level Attention in Action: Dr. Meyer now has two embeddings: (representing her collaborative circle) and (representing her subject-matter community).
- If the downstream task is to recommend new collaborators, the direct co-author relationship is likely more important. The semantic-level attention might learn weights: , .
- If the task is to classify her research field, the community of authors working on similar topics might be more telling. The weights could be: , .
The final embedding is then computed as , providing a task-aware representation of Dr. Meyer.
HGT (Heterogeneous Graph Transformer) #
HGT [5] is a more recent and dynamic approach for heterogeneous graphs. It adapts the powerful Transformer architecture to graphs, avoiding the need for pre-defined meta-paths. HGT excels where relationships are numerous and dynamic, and defining all meaningful meta-paths is impractical. By parameterizing its attention mechanism based on node and edge types, it can dynamically learn the importance of different relationships without prior specification.
Like HAN, HGT has shown state-of-the-art results in academic network analysis, particularly for node classification in large, evolving bibliographic datasets [5]. Its key advantage is not needing to pre-specify meta-paths, allowing it to discover novel, important relationships on its own. A rapidly growing application area for HGT is in knowledge graph completion and recommendation. In large-scale knowledge graphs (e.g., Freebase, Wikidata) or e-commerce product graphs, the number of node and edge types can be in the hundreds or thousands. HGT’s dynamic, type-aware attention mechanism is highly effective at modeling these complex interactions to predict missing links or recommend products to users based on a wide variety of relationships (e.g., user-viewed-product, product-in-category, product-by-brand).
HGT models heterogeneity by parameterizing the weight matrices in its attention mechanism based on node and edge types. For any two nodes and the edge between them, HGT computes attention in a way that is specific to their types, allowing for a more flexible and direct modeling of interactions.
Mathematical Formulation #
The core of HGT is its Heterogeneous Mutual Attention mechanism. To calculate the message from a source node to a target node at layer :
- Type-Specific Projections: Project features into Query, Key, and Value vectors using type-specific matrices. Let be the type of node and be the type of edge .
- Attention Calculation: Use a scaled dot-product attention that also incorporates an edge-type-specific matrix .
- Message Calculation & Aggregation: Aggregate messages from all neighbors.
- Update: Use a residual connection, similar to a standard Transformer block.
High-level comparison of GraphSAGE, HAN, and HGT #
| Feature | GraphSAGE | HAN | HGT |
|---|---|---|---|
| Graph Type | Homogeneous | Heterogeneous | Heterogeneous |
| Core Idea | Scalable sampling of neighbors for inductive learning. | Hierarchical attention over nodes and pre-defined meta-paths. | Transformer-style attention dynamically adapted for node and edge types. |
| Neighborhood | Fixed-size uniform sample. | Full neighborhood, partitioned by meta-paths. | Full neighborhood. |
| Heterogeneity | Not handled. Assumes uniform node/edge types. | Explicitly modeled via meta-paths and semantic-level attention. | Dynamically modeled via type-specific projection matrices for nodes and edges. |
| Key Mechanism | Neighborhood Sampling + Aggregator (Mean/Pool/LSTM). | Node-level & Semantic-level Attention. | Heterogeneous Mutual Attention (Transformer-like). |
GraphSAGE, HAN, and HGT represent a clear progression in GNN design. GraphSAGE provides a powerful and scalable baseline for homogeneous graphs. HAN introduces a sophisticated way to handle heterogeneity by incorporating domain knowledge through meta-paths. HGT builds upon this by removing the dependency on pre-defined meta-paths, using a more flexible and powerful Transformer-based attention mechanism that dynamically learns the importance of different types of relationships directly from the graph structure. The choice between them depends on the nature of the graph data: for simple, homogeneous graphs, GraphSAGE is a strong choice, while for complex, heterogeneous graphs, HGT often provides superior performance due to its dynamic and expressive architecture.
References #
-
Hamilton, W. L., Ying, R., & Leskovec, J. (2017). Inductive representation learning on large graphs. In Advances in neural information processing systems (NIPS).
-
Ying, R., He, R., Chen, K., Eksombatchai, P., Hamilton, W. L., & Leskovec, J. (2018). Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining.
-
Wang, X., Ji, H., Shi, C., Wang, B., Cui, P., Yu, P. S., & Ye, Y. (2019). Heterogeneous graph attention network. In The World Wide Web Conference (WWW).
-
Liu, Z., Chen, C., Yang, X., Zhou, J., Li, X., & Song, L. (2020). Heterogeneous graph neural networks for malicious account detection. In Proceedings of the 29th ACM international conference on information & knowledge management (CIKM).
-
Hu, Z., Dong, Y., Wang, K., & Sun, Y. (2020). Heterogeneous graph transformer. In Proceedings of The Web Conference (WWW).