
The Spectral Mixture (SM) Kernel
The Spectral Mixture (SM) Kernel for Gaussian Processes #
Author: Christoph Würsch, ICE, Eastern Switzerland University of Applied Sciences, OST
Table of Contents #
The Gaussian Process as a Distribution over Functions #
In the realm of machine learning, most models are parametric; they are defined by a set of parameters (e.g., the weights of a neural network), and our goal is to find the optimal based on the data. Gaussian Processes (GPs) [1] offer a fundamentally different, non-parametric perspective. Instead of learning parameters for a specific function, a Gaussian Process places a probability distribution directly over the space of all possible functions. This ”distribution over functions” provides a powerful and principled framework for Uncertainty Quantification (UQ). A GP does not just yield a single point prediction ; it provides an entire Gaussian distribution for any new input , where is the most likely prediction and explicitly quantifies the model’s uncertainty about that prediction. Formally, a Gaussian Process is defined as follows:
Definition A Gaussian Process (GP) is a collection of random variables, any finite number of which have a joint Gaussian distribution.
A GP is fully specified by a mean function and a covariance function :
The mean function represents the expected value of the function at input . For simplicity, this is often assumed to be zero, , after centering the data. The true ”heart” of the GP is the covariance function, or kernel, . The kernel’s role is to encode our prior assumptions about the function’s properties, such as its smoothness, stationarity, or periodicity. It defines the ”similarity” between the function’s output at two different points, and . If two points are ”similar” according to the kernel, their function values are expected to be highly correlated.
The Kernel as a High-Dimensional Covariance Matrix #
The definition of a GP elegantly connects the infinite-dimensional concept of a ”function” to the finite-dimensional mathematics we use for computation. Given a finite dataset of input points, , the joint distribution of the corresponding function values is, by definition, a high-dimensional Multivariate Gaussian. The covariance matrix of this Multivariate Gaussian is constructed by evaluating the kernel function at every pair of points in our dataset:
Thus, our prior belief about the function at the points is expressed as:
The choice of kernel entirely determines the covariance matrix , which in turn defines the properties of all functions sampled from this prior.
The RBF Kernel: The ”Workhorse” of GPs #
While countless kernels exist, the most common and arguably most important is the Radial Basis Function (RBF) kernel, also known as the Squared Exponential or Gaussian kernel. Its enduring popularity stems from its simplicity and its strong, yet often reasonable, prior assumption: smoothness. The RBF kernel is defined as:
This kernel is defined by two hyperparameters:
- Signal Variance (): This is an amplitude parameter. It controls the total variance of the function, scaling the covariance values up or down. It represents the maximum expected variation from the mean.
- Lengthscale (): This is the most critical parameter. It defines the ”characteristic distance” over which the function’s values are correlated.
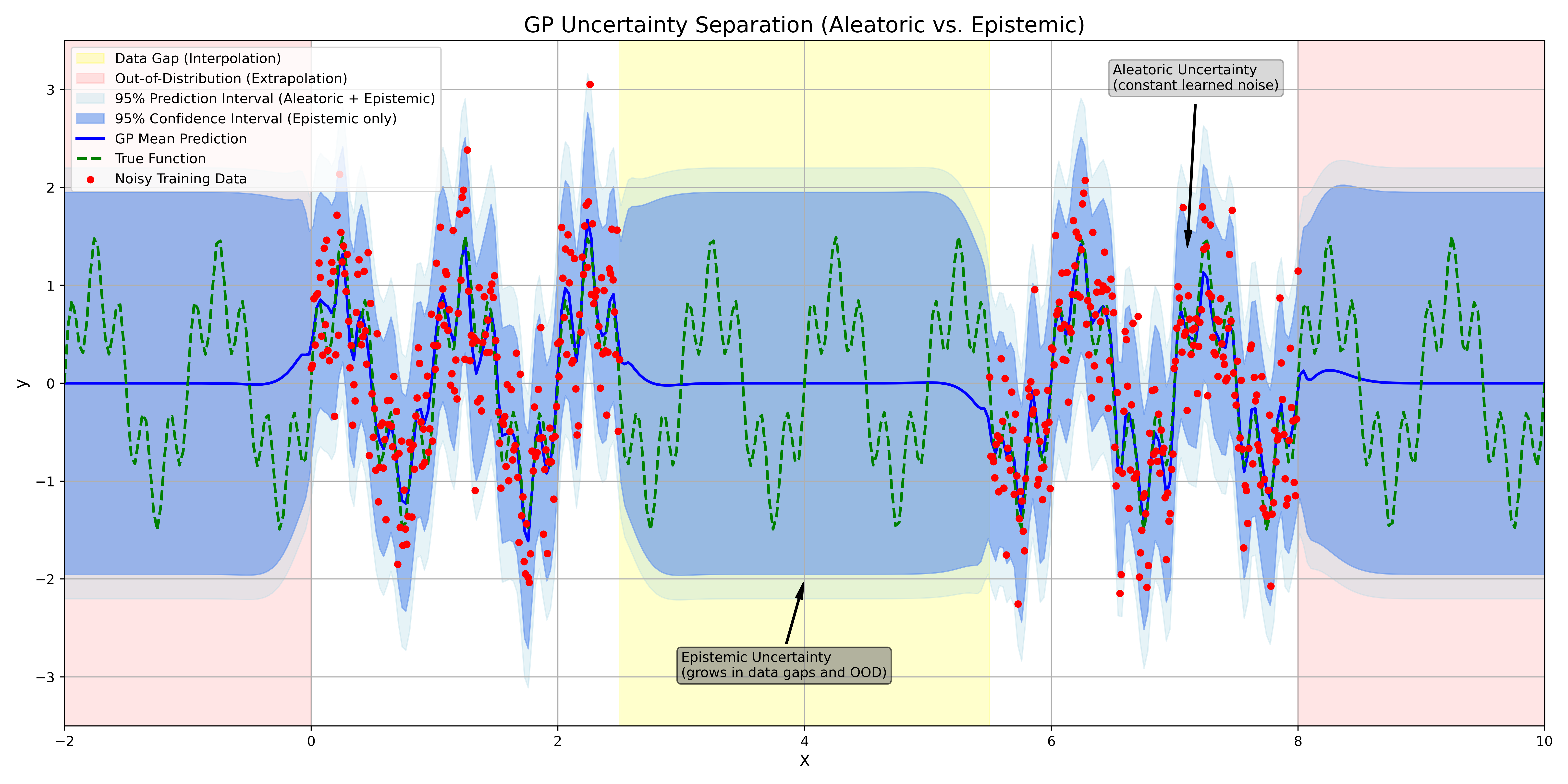
The RBF kernel is stationary (it depends only on the distance , not on the absolute locations) and infinitely smooth. A small lengthscale means the correlation drops off quickly, allowing the function to vary rapidly. A large means that even distant points are correlated, resulting in a very smooth, slowly varying function. When we use an RBF kernel, we are placing a prior on functions that we believe to be smooth. The core idea of GP regression, which we will explore in the following sections, is to take this high-dimensional Gaussian prior built from our RBF kerneland condition it on our finite set of noisy observations . This conditioning step updates our prior belief, yielding a posterior Gaussian Process that provides both the mean prediction and, crucially for UQ, the predictive uncertainty at any unobserved location.
The Limitations of Standard Kernels #
In the application of Gaussian Processes (GPs), we have seen that the choice of kernel is paramount. It encodes all our prior assumptions about the function we are modeling. A popular and widely-used kernel is the Radial Basis Function (RBF) kernel, also known as the Squared Exponential:
where is the distance between inputs, is the signal variance, and is the characteristic lengthscale. The RBF kernel is a ”universal” kernel in the sense that it can approximate any continuous function given enough data. However, its implicit assumptions are very strong. The RBF kernel is infinitely smooth and stationary. Its primary assumption is that ”nearness” in the input space implies ”nearness” in the output space. This makes it an excellent choice for interpolation and smoothing.
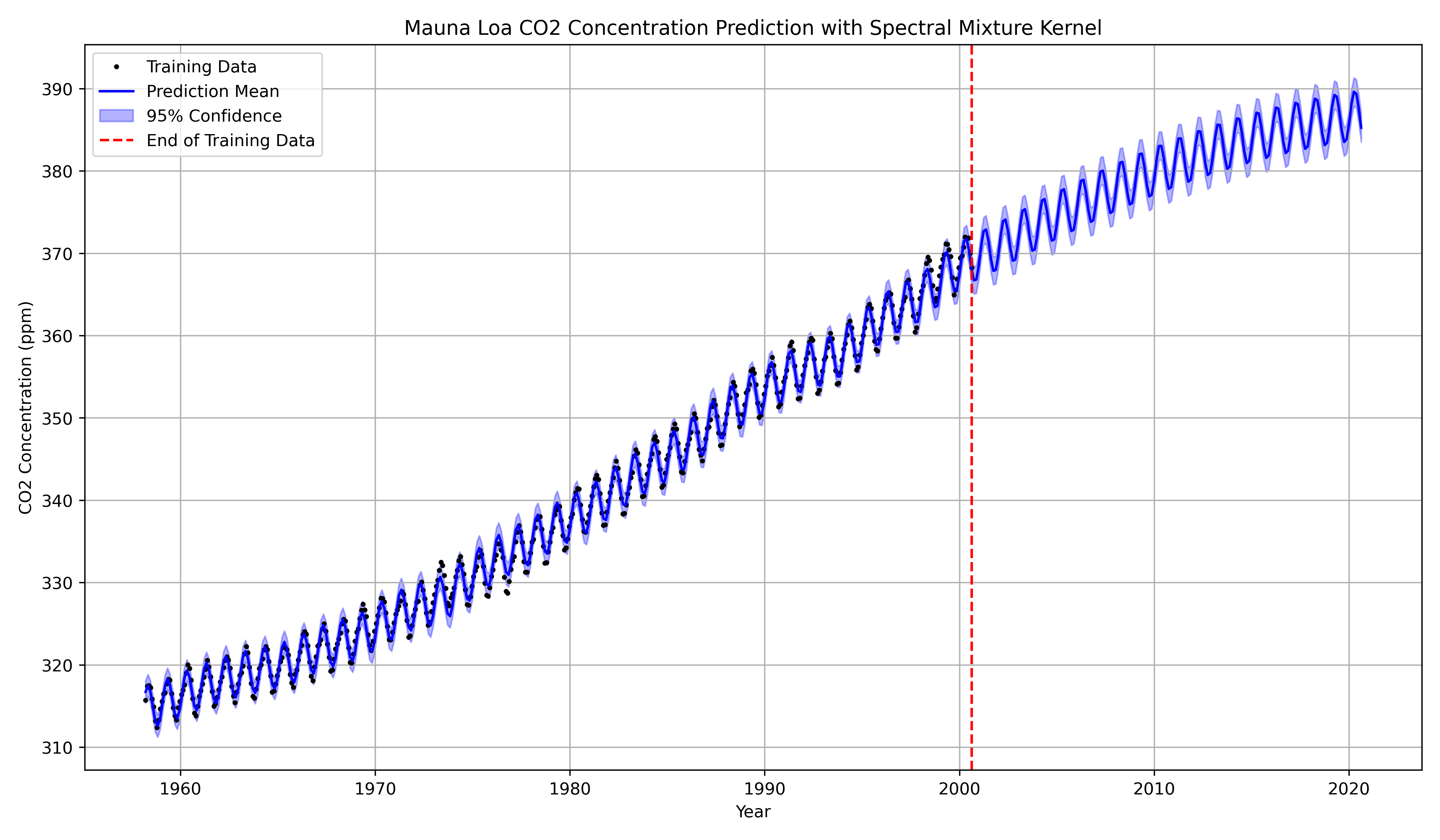
Its weakness, however, is revealed in extrapolation and pattern discovery. Consider the famous Mauna Loa dataset, which exhibits a clear long-term upward trend combined with a strong annual periodicity.
- An RBF kernel can model the long-term trend, but it will fail to capture the periodicity. When asked to extrapolate, its prediction will revert to the mean.
- A
Periodickernel can capture the seasonality, but it must be multiplied by an RBF kernel to allow for local variations, and crucially, the user must specify the period (e.g., 1 year) in advance. This motivates the need for a kernel that does not just apply a predefined structure (like ”smooth” or ”periodic with period ”) but can discover complex, quasi-periodic, and multi-scale patterns directly from the data.
The Spectral Mixture (SM) Kernel [2] #
The Spectral Perspective: Bochner’s Theorem #
The key to developing a more expressive kernel lies in the frequency domain. A fundamental result in mathematics, Bochner’s Theorem, provides the bridge.
Theorem (Bochner, 1959) A complex-valued function on is the covariance function of a stationary Gaussian Process if and only if it is the Fourier transform of a non-negative, finite measure .
For a stationary kernel where , this relationship is:
is known as the spectral density (or power spectrum) of the kernel. It describes the ”power” or ”strength” of the function at different frequencies . Let’s re-examine our standard kernels through this lens:
- RBF Kernel: The spectral density of is also a Gaussian, centered at zero frequency: This mathematically confirms our intuition: the RBF kernel is a strong low-pass filter. It assumes all the function’s power is concentrated at low frequencies (i.e., the function is smooth).
- Periodic Kernel: The spectral density of a purely periodic kernel is a series of delta functions at the fundamental frequency and its harmonics. This is an extremely rigid structure.
The problem is clear: standard kernels have fixed, simple spectral densities. If the true function’s spectrum is complex (e.g., a mix of several periodicities), these kernels will fail to capture it.
The Spectral Mixture (SM) Kernel #
The groundbreaking idea of the Spectral Mixture (SM) kernel, introduced by Wilson and Adams (2013) [2], is this: Instead of assuming a fixed spectral density, let’s learn it from the data.
How can we model an arbitrary, non-negative spectral density ? We can use a Gaussian Mixture Model (GMM), which is a universal approximator for densities. The SM kernel proposes to model the spectral density as a sum of Gaussian components. To ensure the resulting kernel is real-valued, the spectrum must be symmetric, . We thus define the spectral density as a mixture of pairs of symmetric Gaussians:
where each component has a weight , a mean frequency , and a spectral variance . Now, we apply Bochner’s theorem and compute the inverse Fourier transform of to find the kernel . We use the standard Fourier transform pair:
By applying this to our symmetric GMM and using Euler’s formula (), the sum of the -th pair of complex exponentials simplifies beautifully into a cosine function. This yields the Spectral Mixture (SM) Kernel for 1D inputs ():
Spectral Mixture (SM) Kernel (1D)
This kernel is a linear combination of components, where each component is a product of an RBF-like kernel and a periodic cosine kernel. The power of the SM kernel comes from the interpretability of its hyperparameters. For each of the components, we learn:
- Weight (): The component’s overall contribution (amplitude) to the final covariance.
- Mean Frequency (): The center of the component in the frequency domain. This directly controls the periodicity. The period is .
- Spectral Variance (): The variance of the component in the frequency domain. This controls the lengthscale in the time domain ().
This structure allows the kernel to model diverse patterns:
- A smooth trend: A component with (zero frequency) and large (short lengthscale) behaves like a standard RBF kernel.
- A strong, stable periodicity: A component with and very small (long lengthscale) behaves like .
- A quasi-periodic function: A component with and models a wave that slowly ”decays” or changes shape over time.
The kernel can be extended to -dimensional inputs . We define . Each component now requires a weight , a mean frequency vector , and a spectral variance vector (assuming a diagonal covariance ). The multivariate kernel is given by:
Spectral Mixture (SM) Kernel (D-Dimensions)
This is a sum of components, where each component is a product over the dimensions:
This structure allows the model to learn different frequencies (e.g., ”daily” in dimension 1, ”weekly” in dimension 2) and different lengthscales for each component in each input dimension.
Pattern Discovery and Extrapolation #
The most significant feature of the SM kernel is that the parameters are all hyperparameters of the kernel. Just as we optimize the lengthscale of an RBF kernel by maximizing the marginal log-likelihood (ML-II), we optimize all parameters of the SM kernel. This optimization process is the pattern discovery. The GP automatically fits the GMM to the data’s ”hidden” spectral density.
Example: The Dataset #
If we apply an SM kernel (e.g., with ) to the Mauna Loa data, the optimization will likely find:
- Component 1 (Trend): , , (long lengthscale) This component captures the long-term, non-periodic, smooth upward trend.
- Component 2 (Seasonality): , , (very long lengthscale). This component explicitly discovers and isolates the 1-year annual cycle.
Because the model has explicitly learned the periodic component , its predictions will extrapolate this pattern into the future, rather than reverting to the mean. This provides state-of-the-art extrapolation for any time-series data that exhibits quasi-periodic behavior (e.g., climate, finance, robotics).
Implementation and Practical Issues #
The SM kernel is available in modern probabilistic programming libraries such as GPyTorch.
import torch
import gpytorch
class SpectralMixtureGP(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood, num_mixtures):
super(SpectralMixtureGP, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean()
# Define the Spectral Mixture Kernel
# num_mixtures is Q
# ard_num_dims is D (here, 1D input)
self.covar_module = gpytorch.kernels.SpectralMixtureKernel(
num_mixtures=num_mixtures,
ard_num_dims=1
)
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
# Example Usage
# Assume train_x, train_y are 1D tensors
likelihood = gpytorch.likelihoods.GaussianLikelihood()
Q = 4 # We choose to search for 4 components
model = SpectralMixtureGP(train_x, train_y, likelihood, num_mixtures=Q)
# !!
CRITICAL STEP: Initialization !!
# The SM loss landscape is highly multi-modal.
# Random initialization will fail.
We must initialize
# from the data's frequency spectrum (periodogram).
model.covar_module.initialize_from_data(train_x, train_y)
# Now, we train the model as usual
# ... (training loop) ...A Critical Caveat: InitializationThe SM kernel’s greatest strength (its flexibility) is also its greatest weakness. With hyperparameters, the optimization landscape for the marginal log-likelihood is highly multi-modal. A naive or random initialization of the parameters will almost certainly get stuck in a poor local optimum. This kernel is not ”plug-and-play” like an RBF kernel.To use it successfully, one must initialize the parameters intelligently. Libraries like GPyTorch and GPy provide helper functions (e.g., initialize_from_data) that perform the following steps:
- Compute the empirical spectral density of the data using a periodogram (e.g., via a Fast Fourier Transform, FFT).
- Fit a GMM to this empirical spectrum.
- Use the parameters of the fitted GMM (the weights, means, and variances) as the starting values for the kernel’s hyperparameters.
This provides the optimizer with a ”good guess” that is already close to a reasonable solution, allowing it to fine-tune the parameters to the true maximum of the marginal log-likelihood.
Take Aways #
The Spectral Mixture kernel is a powerful, expressive tool for Gaussian Process modeling, effectively moving the problem from kernel selection to kernel learning.
| Advantages | Disadvantages |
|---|---|
|
|
When faced with data that exhibits complex, unknown, or quasi-periodic patterns, the SM kernel is one of the most powerful tools in the modern GP toolbox, provided it is used with a proper initialization strategy.