
Gradient Boosting
Gradient Boosting
Author: Christoph Würsch, ICE, Eastern Switzerland University of Applied Sciences, OST
Die Strategie des sequenziellen Lernens
Boosting ist ein mächtiges und weit verbreitetes Ensemble-Lernverfahren im Bereich des Machine Learning. Im Gegensatz zu Bagging-Methoden wie Random Forests, bei denen viele Modelle unabhängig voneinander trainiert und dann aggregiert werden, verfolgt Boosting einen sequenziellen Ansatz. Die Grundidee ist, die Vorhersagekraft vieler schwacher Lerner (sogenannte Weak Learners), die oft nur wenig besser sind als zufälliges Raten, schrittweise so zu bündeln, dass am Ende ein starker Ensemble-Lerner entsteht. Der Schlüssel zum Erfolg von Boosting liegt in seinem iterativen Trainingsprozess, der sich systematisch auf die Fehler der Vorgängermodelle konzentriert.
- Start: Der Prozess beginnt mit einem ersten schwachen Lerner . Dieser Lerner trifft auf dem gesamten Datensatz Vorhersagen und wird unweigerlich Fehler machen.
- Fokussierung: Anstatt den nächsten Lerner auf dem Originaldatensatz zu trainieren, wird der Datensatz oder, im Falle des Gradient Boostings, die Zielvariable für den nächsten Durchgang modifiziert. Dies geschieht, indem den Datenpunkten, die vom vorherigen Modell falsch klassifiziert oder schlecht vorhergesagt wurden, eine höhere Gewichtung zugewiesen wird (wie bei AdaBoost) oder indem die Restfehler (Residuen) des Vorgängers zur Zielgröße des neuen Modells werden (wie bei Gradient Boosting).
- Iteration: Jeder nachfolgende Lerner wird speziell darauf trainiert, die Schwächen und Fehler des aktuellen Gesamtmodells zu beheben. Man könnte sagen, der neue Lerner lernt aus den Versäumnissen seiner Vorgänger.
Am Ende des Prozesses liegen einzelne, schwache Lerner vor. Der finale starke Lerner wird durch eine gewichtete Summe oder Linearkombination dieser schwachen Lerner gebildet:
Wobei:
- der -te schwache Lerner (oft ein kleiner Entscheidungsbaum, auch Stump genannt) ist.
- die Gewichtung dieses Lerners im finalen Ensemble darstellt. Lerner, die bei den schwierigeren (hoch gewichteten) Fällen eine bessere Leistung erbracht haben, erhalten ein höheres , also mehr Einfluss auf die Gesamtentscheidung.
Durch diese sequenzielle und fehlerorientierte Konstruktion ist das resultierende Ensemble in der Lage, auch komplexe Zusammenhänge präzise abzubilden. Der Schlüssel ist die minimale Fehlerakkumulation: Jeder Schritt korrigiert einen Teil des noch bestehenden Fehlers, was insgesamt zu einem Modell mit sehr hoher Vorhersagegenauigkeit führt, das die Fehler der ursprünglichen schwachen Lerner effektiv minimiert und vermeidet.
Der Gradient Boosting Algorithmus
Gradient Boosting ist ein Additive-Modelle-Verfahren, das eine Funktion
aus vielen einfachen Basisfunktionen konstruiert.
Für Regressionsaufgaben mit quadratischer Lossfunktion handelt es sich im Kern um einen Gradientenabstieg im Funktionsraum. Jeder neue Baum approximiert den negativen Gradienten der Lossfunktion. Das hier dargestellte Material basiert inhaltlich auf Masui (2022) [masui2022] und geht mathematisch weit über den Originalartikel hinaus.
Wir betrachten Trainingsdaten
Wir suchen ein Modell , das die quadratische Lossfunktion minimiert:
Gradient Boosting nähert schrittweise durch additive Funktionen an:
wobei die Lernrate ist und typischerweise ein Regressionsbaum.
Für eine allgemeine Lossfunktion lautet der Gradient-Boosting-Algorithmus (Friedman, 2001):
Algorithmus: Gradient Boosting
Initialisiere
Für : a. Berechne die negativen Gradienten (Pseudo-Residuals)
b. Fit eines Regressionsbaums auf die Residuen:
c. Für jedes Blatt bestimme
d. Update
Im Folgenden leiten wir diese Schritte für die quadratische Lossfunktion vollständig her.
Herleitung der Formeln für einen Regressions-Tree mit quadratischer Verlustfunktion (L2)
Wir wollen folgendes zeigen: Bei L2-Regression sind die Blattwerte Mittelwerte der Residuen.
Wir minimieren
Ableitung:
Daraus folgt:
Fazit: Bei L2-Regression ist gerade der Mittelwert der Response .
Wir berechnen die Pseudo-Residuals
Bis auf den Faktor gilt:
also genau der Residuumvektor. Für jedes Blatt minimieren wir:
Ableitung:
Setzen wir gleich Null:
Damit:
Interpretation als Gradientenabstieg
Ein wesentlicher theoretischer Zugang zu Gradient Boosting besteht darin, den Algorithmus nicht primär als Ensembleverfahren zu betrachten, sondern als eine Form des Gradientenabstiegs im Funktionsraum. Dieser Blickwinkel erlaubt eine präzise mathematische Beschreibung des Verfahrens und erklärt zugleich, weshalb Gradient Boosting in so vielen praktischen Anwendungen eine aussergewöhnlich hohe Leistung erzielt.
Wir betrachten den Raum aller reellwertigen Funktionen, die Eingaben aus auf reelle Zahlen abbilden:
Jedes Modell, das wir in einer Regressionsaufgabe konstruieren, ist ein Element dieses Funktionsraumes. Unser Ziel besteht darin, eine Funktion zu finden, die die vorgegebene Verlustfunktion minimiert. Für Trainingsdaten formulieren wir das Optimierungsproblem als
Im Gegensatz zu klassischen Optimierungsverfahren, die Parametervektoren aktualisieren, führt Gradient Boosting eine Optimierung über Funktionen durch. Dies bedeutet, dass wir nicht an einem endlichen Parametervektor arbeiten, sondern an einer unendlichdimensionalen Struktur – einem Raum von Funktionen.
Der Gradient der Lossfunktion im Funktionsraum ist ein Objekt, das an jedem Trainingspunkt eine Richtung angibt, in die die Modellfunktion verändert werden sollte, um den Wert der Lossfunktion am stärksten zu verringern. Dieser funktionale Gradient wird durch die partiellen Ableitungen
beschrieben und bildet einen Vektor im diskreten Raum der Trainingspunkte.
Gradient Boosting konstruiert nun schrittweise eine Modellfolge , indem es in jeder Iteration einen Schritt in Richtung des negativen Gradienten ausführt:
Hierbei bezeichnet die Lernrate, welche die Grösse des Schrittes im Funktionsraum kontrolliert. Je kleiner die Lernrate gewählt wird, desto feiner sind die Korrekturen, die das Modell pro Iteration durchführt.
Approximation des funktionalen Gradienten durch Entscheidungsbäume
Ein zentrales Problem besteht darin, dass wir den funktionalen Gradient nicht direkt als Funktion auswerten können: Wir kennen den Gradienten nur an den diskreten Trainingspunkten . Ein echter Gradient im Funktionsraum wäre jedoch eine Funktion über dem gesamten Definitionsbereich.
Gradient Boosting löst dieses Problem elegant, indem es eine Funktion konstruiert, die die Werte des negativen Gradienten an den Trainingspunkten so gut wie möglich approximiert:
Die entscheidende Idee lautet:
Diese approximierende Funktion wird durch einen Regressionsbaum dargestellt.
Regressionsbäume sind in der Lage, komplexe und nichtlineare Abhängigkeiten abzubilden, und eignen sich daher hervorragend als Approximation des Gradientenvektors. Da jeder Baum nur eine grobe Schätzung liefert, entsteht durch das sukzessive Hinzufügen vieler kleiner Bäume ein immer präziseres Modell. Aus dieser Perspektive lässt sich die Grundidee des Algorithmus zusammenfassen als:
Jeder Boosting-Schritt fügt dem aktuellen Modell eine neue Funktion hinzu, welche die Richtung des negativen Gradienten approximiert. Damit entsteht schrittweise ein immer besseres Modell, das dem wahren Minimierer der Lossfunktion näher kommt. Diese Sichtweise erklärt nicht nur die theoretische Fundierung des Verfahrens, sondern auch dessen praktische Stärke: Gradient Boosting kombiniert die Robustheit des Gradientenabstiegs mit der Flexibilität nichtlinearer Funktionsapproximation durch Entscheidungsbäume.
Python-Code
Datensimulation
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
x = np.linspace(0, 10, 80)
y = 3*np.sin(x) + 0.5*x + np.random.normal(0, 0.4, len(x))
plt.scatter(x, y)
plt.title("Datensimulation")
plt.show()Stump Regressor
from dataclasses import dataclass
@dataclass
class Stump:
thr: float = 0.0
left: float = 0.0
right: float = 0.0
def fit(self, x, y):
order = np.argsort(x)
xs = x[order]; ys = y[order]
best_loss = 1e99
for i in range(1, len(xs)):
t = 0.5*(xs[i-1] + xs[i])
left = ys[xs < t].mean() if np.any(xs < t) else 0
right = ys[xs >= t].mean() if np.any(xs >= t) else 0
pred = np.where(xs < t, left, right)
loss = ((pred - ys)**2).sum()
if loss < best_loss:
best_loss = loss
self.thr, self.left, self.right = t, left, right
def predict(self, x):
return np.where(x < self.thr, self.left, self.right)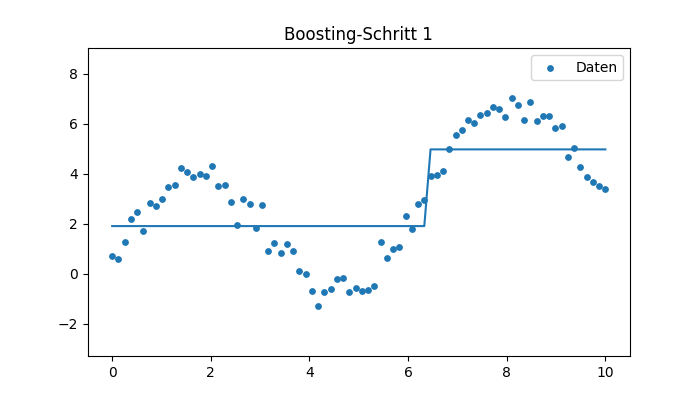
Gradient Boosting
def boost(x, y, M=5, lr=0.3):
F = np.full_like(y, y.mean())
models = []
for _ in range(M):
r = y - F
stump = Stump()
stump.fit(x, r)
F = F + lr * stump.predict(x)
models.append(stump)
return F, models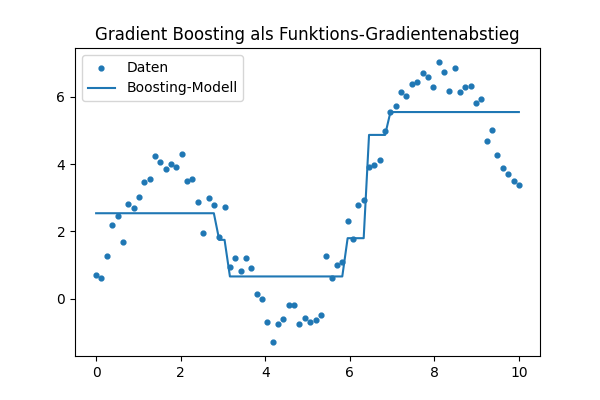
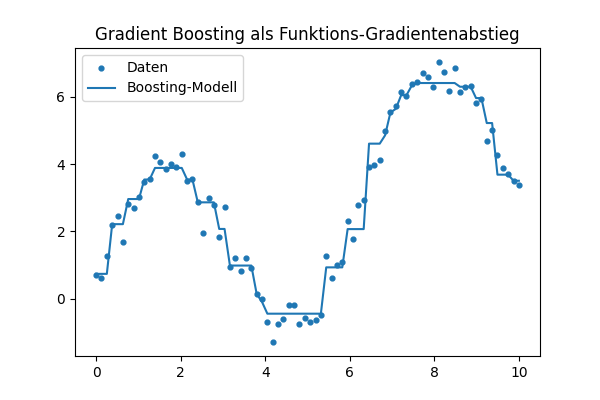
Visualisierung der Boosting-Schritte
F_pred, models = boost(x, y, M=6, lr=0.3)
F = np.full_like(y, y.mean())
steps = [F.copy()]
for stump in models:
F = F + 0.3 * stump.predict(x)
steps.append(F.copy())
for i, Fm in enumerate(steps):
plt.plot(x, Fm, label=f"Iteration {i}")
plt.scatter(x, y, s=10)
plt.legend()
plt.title("Gradient Boosting Schritte")
plt.show()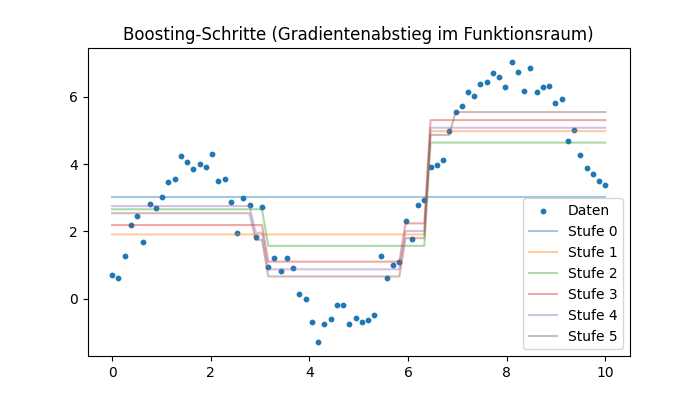
Fazit
Die Herleitung des Gradient-Boosting-Algorithmus zeigt sehr schön, wie eng dieses Verfahren mit der Idee des Gradientenabstiegs verknüpft ist. Während beim klassischen Gradientenabstieg Parameter eines einzigen Modells optimiert werden, arbeitet Gradient Boosting auf einer höheren Ebene: Der Algorithmus führt einen Gradientenabstieg im Funktionsraum durch. Das bedeutet, dass nicht Parameter, sondern ganze Funktionen schrittweise aktualisiert werden. Jede neue Funktion – typischerweise ein kleiner Entscheidungsbaum – wirkt dabei wie ein Korrekturschritt, der die bestehende Modellfunktion in Richtung des negativen Gradienten der Lossfunktion verschiebt.
Für die häufig verwendete L2-Regression lässt sich besonders klar erkennen, wie dieser Mechanismus funktioniert. Der funktionale Gradient der quadratischen Verlustfunktion entspricht exakt den Residuen zwischen Modellvorhersage und Zielwert. Das bedeutet: In jedem Boosting-Schritt wird ein Regressionsbaum an jene Werte angepasst, die das aktuelle Modell noch nicht erklären kann. Diese Residuen repräsentieren also direkt den ”Fehler”, in dessen Richtung sich das Modell verbessern muss. Die Blattwerte des Regressionsbaums – also die vorhergesagten Korrekturwerte in jedem Teilraum – ergeben sich als Mittelwerte der Residuen in den entsprechenden Regionen. Auf diese Weise liefern die Bäume lokal passende Korrekturen, die das Modell präzise weiterentwickeln.
Eine weitere wichtige Eigenschaft ist die Rolle der Lernrate (learning rate). Sie bestimmt die Grösse des jeweiligen Schritts im Funktionsraum und verhindert, dass das Modell zu grosse, instabile Korrekturen vornimmt. Kleine Lernraten führen zwar zu mehr benötigten Iterationen, ermöglichen aber zugleich feinere Anpassungen und reduzieren typischerweise das Risiko des Überfittings. Gradient Boosting ist deshalb nicht nur ein schrittweises, sondern auch ein kontrolliertes Verbesserungsverfahren.
Diese Kombination aus funktionalem Gradientenabstieg, residuenbasierten Korrekturen und fein steuerbaren Schrittweiten macht Gradient Boosting zu einer der leistungsfähigsten Methoden des überwachten Lernens. Besonders stark ist das Verfahren bei tabellarischen, heterogenen oder nichtlinear strukturierten Daten, wo lineare Modelle oder tiefere neuronale Netze häufig an ihre Grenzen stossen. Moderne Varianten wie XGBoost, LightGBM oder CatBoost erweitern diese Grundidee um Regularisierung, effiziente Implementierungen und weitere Optimierungen – und erreichen damit in vielen praktischen Anwendungen State-of-the-Art-Ergebnisse.
Gradient Boosting wird heute erfolgreich eingesetzt in Aufgaben wie der Vorhersage von Immobilienpreisen, im Risikoscoring im Finanzwesen, bei Zeitreihen mit nichtlinearen Effekten, in der medizinischen Diagnostik sowie allgemein überall dort, wo robuste, hochperformante Modelle für strukturierte Daten benötigt werden. Die theoretische Eleganz und die praktische Leistungsfähigkeit machen Gradient Boosting zu einem der zentralen Werkzeuge im Werkzeugkasten des modernen Machine Learnings.
Anhang: Funktionale Ableitung und geometrische Interpretation
In diesem Abschnitt leiten wir die funktionale Ableitung (den Gradienten im Funktionsraum) für das empirische Risiko explizit her und geben anschliessend eine geometrische Interpretation. Der zentrale Punkt ist, dass sich Gradient Boosting als Gradientenabstieg in einem (endlichen) Funktionsraum interpretieren lässt, in dem die Funktionswerte auf den Trainingspunkten die Rolle von Koordinaten spielen.
Wir betrachten wie zuvor Trainingsdaten
und ein Modell .
Das empirische Risiko definieren wir allgemein als
wobei eine differenzierbare Verlustfunktion ist.
Wichtig ist nun die Beobachtung: Für die Optimierung auf den Trainingsdaten genügt es, die Funktionswerte
zu betrachten. Aus Sicht der Optimierung können wir also den Vektor
als die relevanten Parameter ansehen, auf denen das empirische Risiko tatsächlich beruht. Damit ist das Risiko eine Funktion
Die (diskrete) Gradientenableitung nach den Komponenten ist dann
da jeder Summand für unabhängig von ist. Der Gradient von bezüglich der Funktionswerte ist also der Vektor
Dies ist genau der Vektor der partiellen Ableitungen der Lossfunktion nach den Funktionswerten. Für die in der Regression sehr häufig verwendete quadratische Lossfunktion
ergibt sich für einen einzelnen Summanden
Die Ableitung nach ist
Da konstant ist und , erhalten wir
Damit ist die partielle Ableitung des empirischen Risikos
da alle Terme mit keine Funktion von sind. Der Gradientvektor ist also
Die negative Gradientenrichtung ist damit proportional zum Residuenvektor
Bis auf einen konstanten Faktor gilt also:
Für L2-Regression ist der negative Gradient des empirischen Risikos genau der Vektor der Residuen. Wenn Gradient Boosting also einen Baum auf den Pseudo-Residuen fittet bedeutet, heisst das konkret: Der Baum approximiert den negativen Gradienten der Lossfunktion im Raum der Funktionswerte.
Funktionale Sichtweise
Die obige Herleitung war bewusst diskret und endlichdimensional. In einer etwas abstrakteren (funktionalanalytischen) Sichtweise betrachten wir den Funktionsraum
als einen Vektorraum, in dem sich Funktionen addieren und mit Skalaren multiplizieren lassen. Das empirische Risiko wird dann zu einem Funktional
Die funktionale Ableitung von an der Stelle ist ein Objekt, das jedem Punkt (oder zumindest jedem Trainingspunkt ) einen Ableitungswert zuordnet. Anschaulich gibt die funktionale Ableitung an, wie sich ändert, wenn man in Richtung einer kleinen Störung verändert.
Formal betrachtet man dazu eine Variation mit einem Richtungsfeld und kleinem . Die erste Variation von in Richtung ist durch
gegeben. Im diskreten Fall reduziert sich dies auf
Steht uns ein Skalarprodukt auf dem Funktionsraum (oder im diskreten Fall auf ) zur Verfügung, so lässt sich die erste Variation auch schreiben als
wobei nun als Gradient im Funktionsraum aufgefasst wird. Die Gleichung zeigt: Der Gradient ist genau das Objekt, das in jeder Richtung die Richtungsableitung liefert.
Geometrische Interpretation
Die geometrische Interpretation von Gradient Boosting folgt direkt aus dieser Gradientsicht.
-
Raum der Funktionswerte. Im diskreten Setting auf den Trainingsdaten können wir das Modell mit seinem Vektor der Funktionswerte identifizieren. Dieser Vektor lebt in einem -dimensionalen euklidischen Raum .
-
Gradient als Steilsteigungsrichtung. Der Gradient ist die Richtung, in der die Lossfunktion am stärksten ansteigt. Die negative Gradientenrichtung ist dementsprechend die Richtung des stärksten Abstiegs.
-
Gradientenabstieg. Ein klassischer Gradientenabstieg im Vektorraum könnte als Update schreiben:
Im Funktionsraum formuliert man dies symbolisch als
was genau die Notation ist, die häufig im Kontext von Gradient Boosting verwendet wird.
-
Rolle der Bäume. In der Praxis können wir nicht beliebige Funktionsänderungen wählen, sondern sind auf Funktionen beschränkt, die durch Regressionsbäume darstellbar sind. Jeder Baum stellt also eine approximative Projektion des negativen Gradienten auf den Raum der Baumfunktionen dar:
Das Update
bedeutet geometrisch: Wir bewegen uns von aus in einer Richtung, die möglichst gut mit der Richtung des stärksten Abstiegs übereinstimmt, jedoch innerhalb der erlaubten Modellklasse der Bäume liegt.
-
Schrittweite und Lernrate. Die Lernrate skaliert die Schrittweite. Geometrisch bestimmt sie, wie weit wir in Richtung des approximierten Gradienten gehen. Kleine Lernraten führen zu vielen kleinen Schritten, grosse Lernraten zu wenigen grossen Schritten.
Gradient Boosting kann geometrisch als schrittweiser Abstieg auf der Losslandschaft interpretiert werden, wobei die Position durch die Funktionswerte repräsentiert wird und die Abstiegsrichtung durch den (negativen) Gradienten der Lossfunktion gegeben ist. Regressionsbäume dienen dabei als begrenzte, aber flexible Basisfunktionen, mit denen diese Abstiegsrichtung in jeder Iteration approximiert wird. Dadurch entsteht ein algorithmisch realisierbarer Gradientenabstieg im Funktionsraum.
Referenzen
- [masui2022] Tomonori Masui, All You Need to Know about Gradient Boosting Algorithm – Part 1, 2022.
- [chen2024] Chen, H. (2024). Understanding Gradient Boosting Classifier: Training, Prediction, and the Role of . ArXiv, abs/2410.05623.
- [friedman2001] Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, pages 1189–1232.